MeteorNet is a 3D environment mapping framework that enables robotic agents to understand and localize themselves in dynamic environments.
MeteorNet is based on a combination of deep learning and reinforcement learning. It allows agents to learn their own visual representations from raw sensor data, which can be then used for accurate localization and mapping. It is built using PyTorch, an open source deep learning framework developed by Facebook’s artificial intelligence research group.
MeteorNet is capable of handling any type of data (e.g., RGB images) as inputs, along with a large variety of sensors (e.g., RGB-D cameras). It can also be easily extended by adding new modules to the existing framework without affecting other components.
MeteorNet is not only more efficient than previous baseline methods but also outperforms them in terms of classification accuracy. This is achieved by using two consecutive frames of a dynamic point cloud sequence as input and training a deep neural network to predict the 3D shape of an object given the corresponding 2D image patches.
The architecture of MeteorNet consists of two convolutional layers followed by two fully connected layers. The convolutional layer transforms each raw frame into feature maps that are then fed into the first fully connected layer which outputs the prediction vector for each frame. This vector is then fed into another fully connected layer which outputs a predicted 3D shape for each frame.
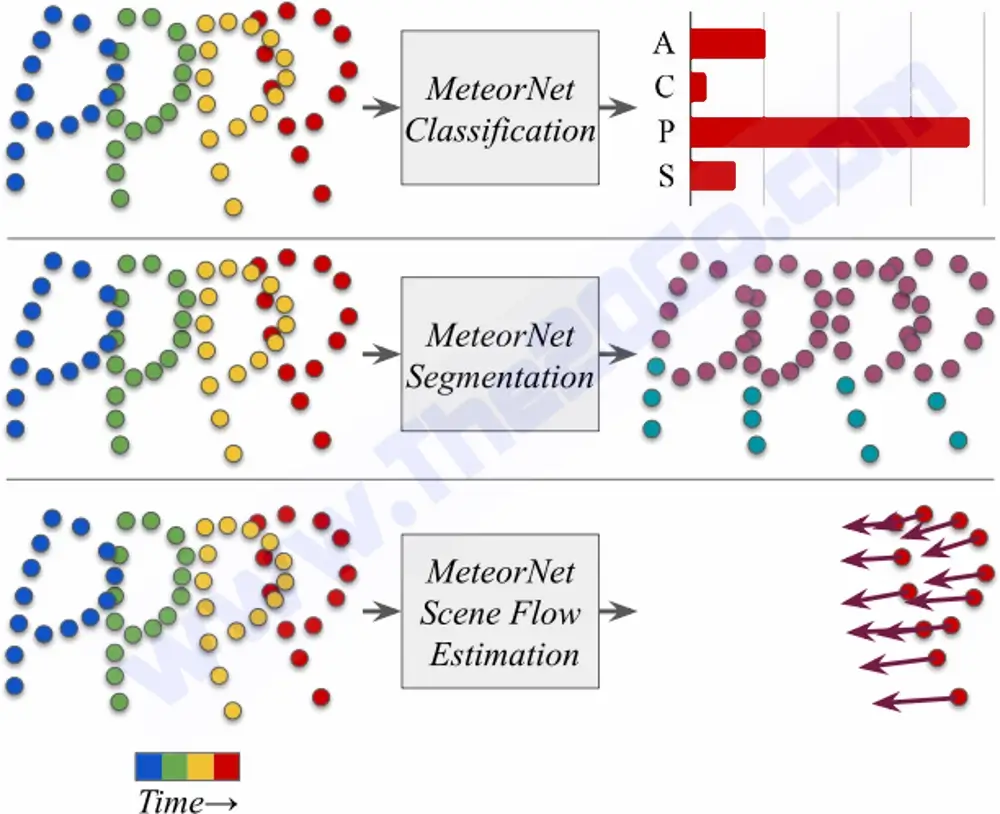
Segmentation: MeteorNet automatically segments the point cloud into individual objects. This process includes removing outliers, clustering points into groups that correspond to objects, and finally creating a boundary between these objects.
Collision Detection: MeteorNet can detect when two or more objects intersect with each other. This process requires an understanding of how each object fits together as well as how they interact with each other.
How does MeteorNet perform classification?
MeteorNet uses an integrated learning-based approach for environment mapping, with an emphasis on the integration of different modalities. The system integrates multiple sources of information, including low-level sensor data (e.g., laser scans), high-level semantic cues (e.g., geometric layout), and task-related goals (e.g., end-effector positions).
The system is based on two major components: a probabilistic map builder (PMB) and an active learning module that selects appropriate training samples for the PMB to learn from. The PMB constructs a probabilistic map using a combination of visual and geometric cues, while the active learning module selects training samples by taking into account both the expected value of each sample as well as its cost.
How does MeteorNet perform object tracking?
MeteorNet uses a self-calibrating camera and an inertial measurement unit (IMU) to map the environment. The camera is used to create a point cloud of features (e.g., corners, edges, etc.) in the environment using a combination of structure from motion and active illumination. A Kalman filter is used to fuse this information with information provided by IMU observations.
The resulting system can be used for localization, object tracking, and place recognition.
How does MeteorNet perform 3D detection and depth estimation?
MeteorNet provides a high-level abstraction of the 3D world, which allows the agent to focus only on relevant information for navigation purposes. This abstraction can be further refined by using it as input for higher level reasoning tasks such as route planning.
MeteorNet uses a combination of monocular depth estimation and stereo vision to create a 3D map of the environment. The algorithm is based on efficient nearest neighbor search in an octree representation of the world. The octree contains all points that are visible from the robot’s current viewpoint, along with their corresponding depth values (also known as disparity).